Managing logs in a Kubernetes cluster plays a critical role in debugging, monitoring, and ensuring system reliability. Across modern infrastructure, Kubernetes now serves as the default platform for container orchestration. Because this shift has reshaped application deployment, traditional logging methods no longer meet operational needs in cloud-native environments. This article explores scalable logging patterns for Kubernetes clusters to help teams manage logs efficiently. Proven strategies, including DaemonSets and sidecar patterns, appear throughout the discussion.
The Importance of Cluster-Level Logging in kubernetes cluster
Previously, teams stored logs directly on virtual machines or bare metal systems. During that era, this approach worked well because machines remained long-lived and stable. Modern cloud environments, however, introduce a very different challenge for any Kubernetes cluster. Within Kubernetes-based platforms, frequent node termination makes node-bound logs unreliable.
As a result, every production Kubernetes cluster now requires cluster-level logging. Rather than depending on local storage, teams forward logs to centralized and persistent backends.
For example, many organizations use Elasticsearch, GCP Stackdriver, or AWS CloudWatch to store Kubernetes cluster logs. Through centralized storage, engineers can search and analyze logs even after pod crashes or node failures. When expert guidance becomes necessary, ZippyOPS Services delivers consulting, implementation, and managed services for Kubernetes cluster logging architectures.
Types of Logs Generated in Kubernetes cluster
Generally, a Kubernetes cluster produces two primary categories of logs: application logs and system logs.
Application logs originate from containers running inside the Kubernetes cluster. In most cases, the container runtime captures output written to stdout and stderr. This process results in JSON log files stored on the node filesystem.
System logs, meanwhile, come from Kubernetes components such as kube-scheduler and kube-proxy. Beyond these components, the kubelet and container runtime write logs directly to directories like /var/log on cluster nodes.
Common Logging Patterns Used
In practice, Kubernetes clusters support several logging patterns. Among available options, the DaemonSet and sidecar patterns remain the most widely adopted. Each approach, although effective, introduces different trade-offs depending on cluster scale and workload design.
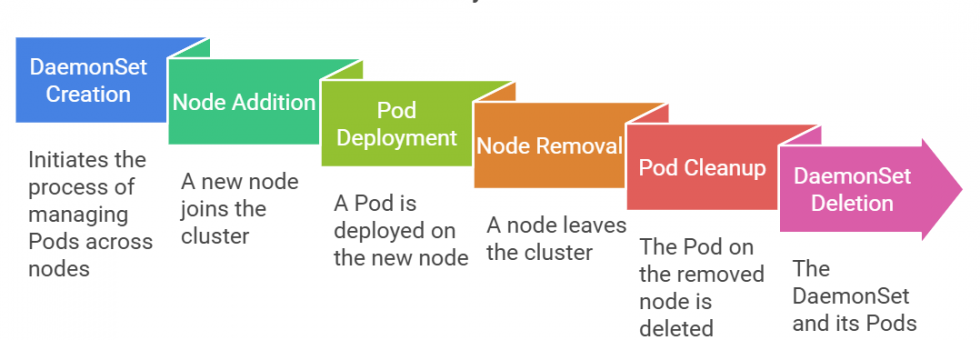
Kubernetes Cluster DaemonSet Logging Pattern
With the DaemonSet logging pattern, operators deploy a logging agent on every node in the Kubernetes cluster. Under this model, each node runs exactly one logging pod. This design ensures centralized log collection from paths such as /var/log.
Pros of DaemonSet Logging
First, resource usage stays low because only one pod runs per node in the Kubernetes cluster.
From an operational standpoint, teams find this pattern easier to implement due to standard file-based logging.
Cons of DaemonSet Logging
However, this approach limits flexibility when applications write logs to files instead of streams.
Over time, teams must manage log retention carefully because node storage remains ephemeral.
Kubernetes Cluster Sidecar Logging Pattern
By contrast, the sidecar logging pattern places a dedicated logging container alongside each application container in the cluster. In this architecture, the sidecar actively collects, processes, and forwards logs.
Types of Sidecars
For example, teams use a streaming sidecar when applications write logs to files instead of stdout. In such cases, the sidecar tails the file and forwards log entries to standard output.
Alternatively, a logging agent sidecar sends logs directly to backends such as Elasticsearch or AWS CloudWatch. This approach completely bypasses node-level storage in the Kubernetes cluster.
Pros of Sidecar Logging
Therefore, this pattern provides significantly higher flexibility for application-specific logging needs.
At the same time, teams eliminate the need for node-level log rotation.
Cons of Sidecar Logging
On the downside, resource consumption increases because each pod includes an additional container.
As deployments scale, operational complexity also increases across the cluster.
Implementing Scalable Logging
To illustrate a real-world approach, teams often use Fluentd as the logging agent. When combined with Elasticsearch and Kibana, this stack forms a scalable logging pipeline suitable for production clusters in kubernetes.
Conclusion
In summary, effective logging in a cluster of Kubernetes depends on choosing the correct strategy. Across most production environments, teams benefit from a hybrid approach. DaemonSets handle node-level logging, while sidecars support specialized workloads.
Ultimately, the choice of backend depends on cost and scalability requirements. For organizations seeking expert implementation, ZippyOPS delivers consulting, implementation, and managed services that help teams operate resilient Kubernetes clusters.



